

High-fidelity noise reduction
with differentiable signal processing
Christian J. Steinmetz1 Thomas Walther2 Joshua D. Reiss1
1Centre for Digital Music, Queen Mary University of London
2Tape It Music GmbH
Abstract
Noise reduction techniques based on deep learning have demonstrated impressive performance in enhancing the overall quality of recorded speech. While these approaches are highly performant, their application in audio engineering can be limited due to a number of factors. These include operation only on speech without support for music, lack of real-time capability, lack of interpretable control parameters, operation at lower sample rates, and a tendency to introduce artifacts. On the other hand, signal processing-based noise reduction algorithms offer fine-grained control and operation on a broad range of content, however, they often require manual operation to achieve the best results. To address the limitations of both approaches, in this work we introduce a method that leverages a signal processing-based denoiser that when combined with a neural network controller, enables fully automatic and high-fidelity noise reduction on both speech and music signals. We evaluate our proposed method with objective metrics and a perceptual listening test. Our evaluation reveals that speech enhancement models can be extended to music, however training the model to remove only stationary noise is critical. Furthermore, our proposed approach achieves performance on par with the deep learning models, while being significantly more efficient and introducing fewer artifacts in some cases.
Citation
@inproceedings{steinmetz2023highfidelity,
title={High-fidelity noise reduction with differentiable signal processing},
author={Steinmetz, Christian J. and Walther, Thomas and Reiss, Joshua D.},
booktitle={155th Convention of the Audio Engineering Society},
year={2023}
}Audio Examples
Speech enhancement systems for music
While speech enhancement models have achieved impressive performance in improving the quality of full-band signals, such as Adobe Enhance Speech and DeepFilterNet, these systems cannot be used to denoise non-speech signals. When running these systems on music recordings they either corrupt the musical content, fail to remove any noise, or completely remove the music signals. The following examples demonstrate results when using speech enhancement models for non-speech sources compared to our proposed approach, which works on all audio sources.
| Name | Noisy | Adobe Enhance Speech | DeepFilterNet2 (Schröter et al.) |
Tape It (ours) |
|---|---|---|---|---|
| AcGtr + Vocal 1 | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| Classical Guitar | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| AcGtr | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| AcGtr + Vocal 2 | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| Jazz Piano | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
Listening test stimuli
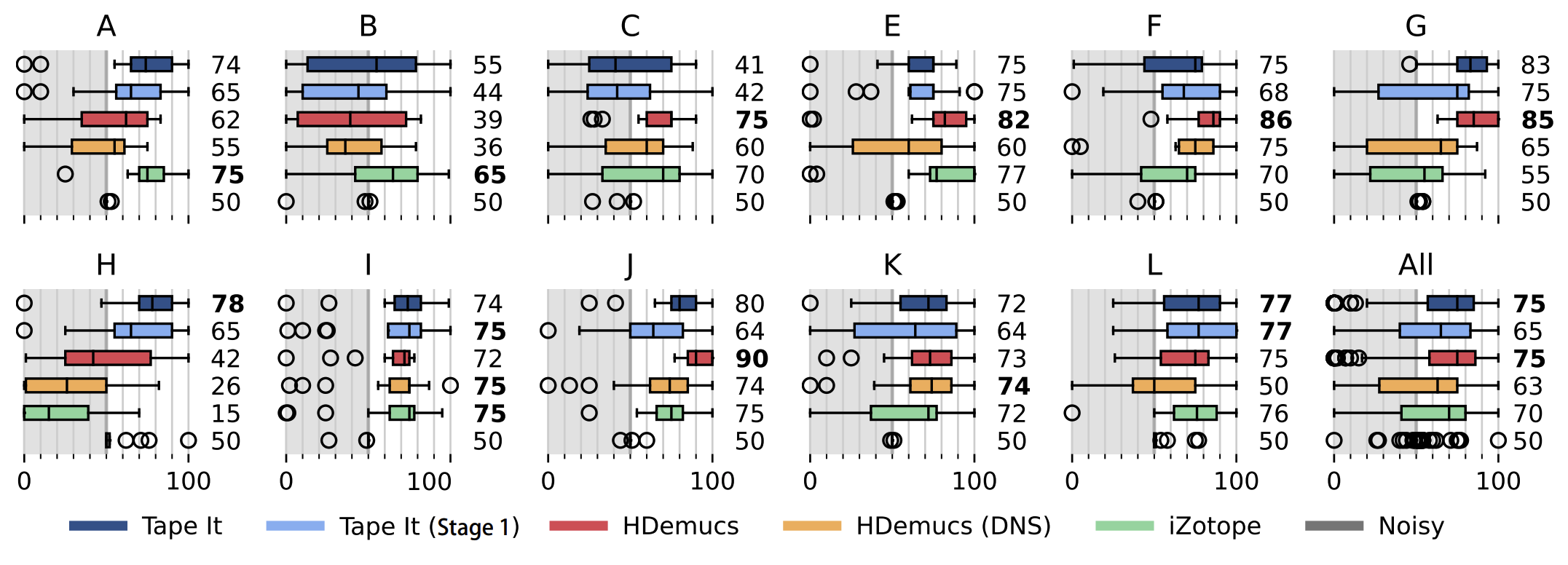
The following examples are denoised recordings used in the perceptual listening test. The results from the listening test are shown below in the boxplot. We compare our proposed method (Tape It) against variants of HDemucs that are trained on the same dataset, as well as iZotope RX Spectral Denoise. We manually adjust the iZotope denoiser selecting a noise-only section when it is available, otherwise we use the automatic mode. We also compare to our model without stage 2 training.
| ID | Noisy | Tape It (ours) |
Tape It (Stage 1) (ours) |
HDemucs | HDemucs (DNS) | iZotope |
|---|---|---|---|---|---|---|
| A | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| B | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| C | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| E | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| F | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| G | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| H | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| I | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| J | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| K | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
| L | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
Test set
The following are selected examples from the held-out test dataset. Here we compare our approach (Tape It) against other models trained on our dataset, including HDemucs and DCUNet. We also compare here against RNNoise, which was pretrained for speech enhancement.
| Source | Noise | Noisy | Tape It (ours) |
HDemucs | HDemucs (DNS) | DCUNet | RNNoise |
|---|---|---|---|---|---|---|---|
| GuitarSet | Freesound | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
| DSD100 | Tape It (Internal) | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
| VCTK | Tape It (Internal) | 0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
||
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|
0:00
0:00
|